

Simple RL
December 10, 2016
I just finised up the alpha version of simple_rl, a library for running Reinforcement Learning experiments in Python 2 and 3. The library is designed to generate quick and easily reproducible results. As the name suggests, it's intended to be simple and easy to use. In this post I'll give an overview of the features of the library through by going over some example experiments, which I'm hoping serves as a mini tutorial. I'll assume those reading this are familiar with Reinforcement Learning (RL). For those not - I suggest reading Ian Osband's excellent writeup introducing RL.
To install, simply enter:
Or clone the repository linked above and install via the usual:
python setup.py install.
The only dependencies are numpy and matplotlib, though if you want to run experiments in the OpenAI Gym, you'll also need that installed.
Example 1: Grid World
The main workhorse for simple_rl is the run_agents_on_mdp function from the run_experiments sub module (simple_rl.run_experiments). This function takes a list of Agents and an MDP instance as input, runs each agent on the MDP, stores all results in cur_dir/results/mdp-name/*, and generates (and opens) a plot of the learning curves. We can also control various parameters of the experiment, like the number of episodes, the number of steps an agent takes per episode, and the number of total instances of each agent type to run (for confidence intervals).
For example, the following runs Q-Learning on a simple grid world MDP:
# Imports
import simple_rl
from simple_rl.agents import QLearningAgent
from simple_rl.tasks import GridWorldMDP
from simple_rl.run_experiments import run_agents_on_mdp
# Setup MDP, Agents, and run.
mdp = GridWorldMDP(10, 10, goal_locs=[(10,10)])
ql_agent = QLearningAgent(mdp.get_actions())
run_agents_on_mdp([ql_agent], mdp, steps=100)
Running this will output relevant experiment information (which is also stored in the same directory as the results), and will continually update the status of the experiment to the console:
Running experiment:
(MDP)
gridworld_h-10_w-10
(Agents)
Q-learning,0
(Params)
track_disc_reward : False
instances : 5
episodes : 100
steps : 100
is_lifelong : False
gamma : 0.99
Q-learning is learning.
Instance 1 of 5.
When the experiment is finished (which on my laptop takes around 2 seconds), the console produces the following:
--- TIMES ---
Q-learning agent took 1.94 seconds.
-------------
Also, a plot showing the learning curves of any run algorithms will open:
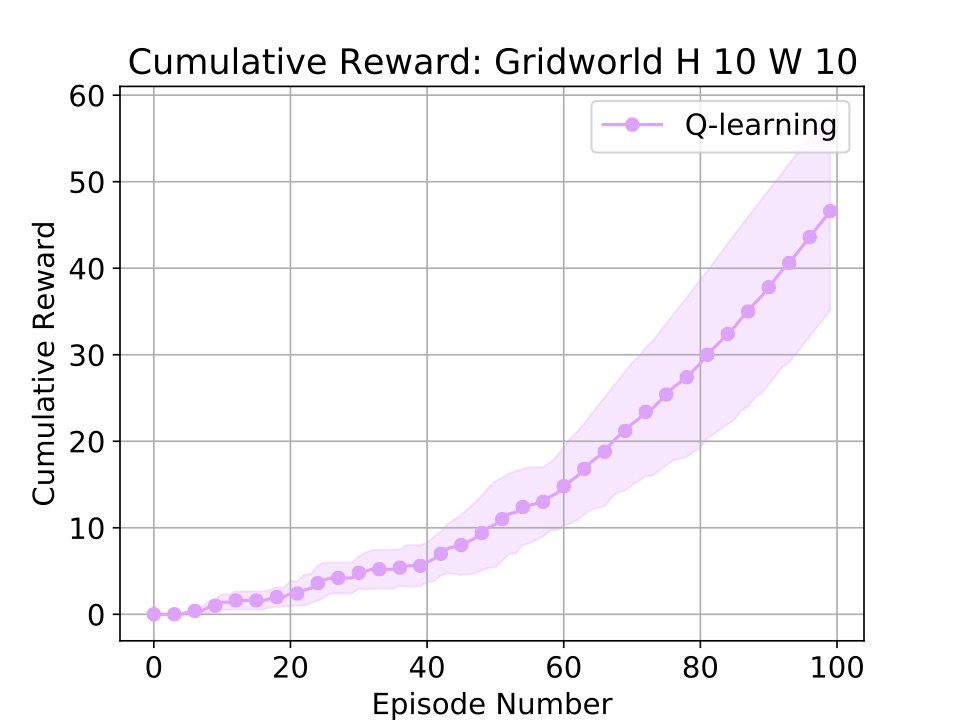
Simple! If you want to control various knobs of the experiment (like the number of steps taken per episode or the number of episodes) these are paramteres to the run_agents_on_mdp function. For instance, if we wanted to run each 5 instances of the experiment for 100 episodes each, with 25 steps per episode, we would call the following:
run_agents_on_mdp([ql_agent], mdp, episodes=50, instances=5, steps=25)
Example 2: Taxi
In addition to defining MDPs using a traditional state enumeration method, simple_rl has support for defining MDPs with an Object-Oriented Representation, introduced by [Diuk et al. 2008]. With objects it becomes much easier to code up more complex problems, such as the Taxi problem from [Dietterich 2000].
Running experiments on Taxi is nearly identical to the above example. The only added complexity is specifying certain properties of the Taxi instance:
- Where does the agent start?
- How many passengers are there, where do they start, and where is their destination?
- Where are walls located? (if any exist)
Let's also add a randomly acting agent. To set up the Taxi MDP we'll end up with:
# Imports
from simple_rl.agents import QLearningAgent, RandomAgent
from simple_rl.tasks import TaxiOOMDP
from simple_rl.run_experiments import run_agents_on_mdp
# Setup Taxi OO-MDP.
agent = {"x":1, "y":1, "has_passenger":0}
passengers = [{"x":4, "y":3, "dest_x":2, "dest_y":2, "in_taxi":0}]
walls = []
taxi_mdp = TaxiOOMDP(5, 5, agent_loc=agent, walls=walls, passengers=passengers)
# Setup agents and run.
ql_agent = QLearningAgent(taxi_mdp.actions)
rand_agent = RandomAgent(taxi_mdp.actions)
run_agents_on_mdp([ql_agent, rand_agent], taxi_mdp)
Running the above code produces (and opens) the following plot in about 1 second on my laptop:
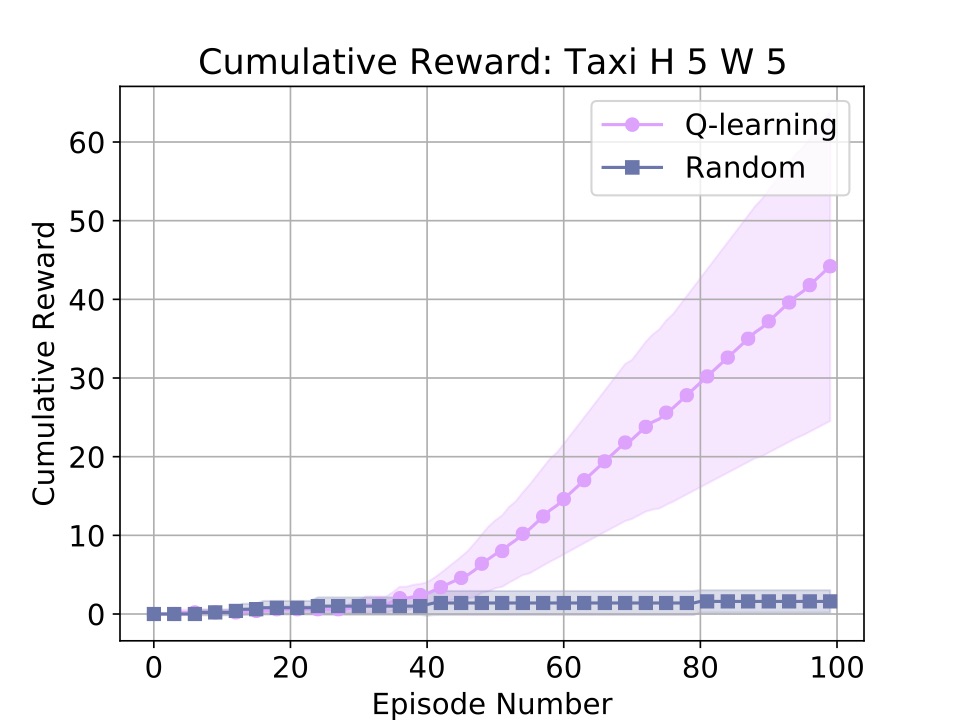
Aha! Learning.
Example 3: OpenAI Gym (Breakout)
To run experiments in the gym, the setup is almost identical:
# Imports
from simple_rl.agents import RandomAgent, DQNAgent
from simple_rl.tasks import GymMDP
from simple_rl.run_experiments import run_agents_on_mdp
# Gym MDP
gym_mdp = GymMDP(env_name='Pong-v0', render=True)
# Setup agents and run.
rand_agent = RandomAgent(gym_mdp.get_actions())
dqn_agent = DQNAgent(gym_mdp.get_actions())
run_agents_on_mdp([dqn_agent, rand_agent], gym_mdp, instances=3, episodes=1, steps=200)
Also note here we set the number of episodes to 1, so the x-axis of the generated plot automatically switches to per-step cumulative reward across instances instead of per-episode. The instances flag is how many of the same instance of each algorithm to run to compute confidence intervals.
Those are the basics! The library also includes support for things like planning, abstractions (like Options from [Sutton, Precup, Singh 1999]), and bandits.
If you want to get started yourself, I'd encourage you to check out the examples directory.
Code Overview
The code of simple_rl basically consists of the following:
- An MDP class (with an OO-MDP and Markov Game subclass)
- A State class.
- Some standard MDPs, including:
- Grid World
- N-Chain
- Taxi
- Gym
- Some basic Agent implementations:
- Q-Learning
- R-Max
- Q-Learning with a Linear Function Approximator
- Randomly Acting Agent
- Planning methods, like Value Iteration and MCTS (under development).
- Utilites to handle plotting and running experiments
Adding an MDP
To add a new MDP, make an MDP subclass with the following components:
- State: A companion State subclass that contains domain relevant data (if it's just a single datum or an image you can use StateClass and ImageStateClass respectively)
- Actions: A static list of strings called ACTIONS, each element denoting an action.
- Rewards: A private method _reward_func that takes a State (of the type from 1.) and an action (from ACTIONS) and outputs a number.
- Transitions: A private method _transition_func that takes as input a State and action (same rules) and outputs another State.
- Initial State: You'll also need to create an initial state (or generative model of initial states) to pass into the MDP constructor.
That's it! If you want to make an OO-MDP, take a look at the TaxiMDP Implementation.
Adding an Agent
To add a new Agent, make an AgentClass subclass with the following properties an act method that takes as input a State and Reward (float) and outputs an action in the MDP's ACTION list. Typically the structure is that the agents each take as input an ACTION list which they hand off in a super call. That's it! Check out RandomAgentClass for a simple example
I hope some folks find this useful! Let me know if you have suggestions or come across any bugs.
Cheers!
-Dave